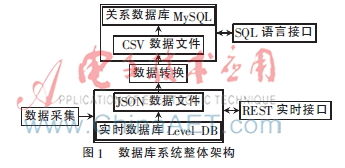
随着企业信息化建设的深入发展,不同的业务部门或不同时期引入的应用系统往往采用不同的数据库技术,如关系型数据库(MySQL, PostgreSQL, Oracle)、NoSQL数据库(MongoDB, Redis)、以及数据仓库(Hive, ClickHouse)等,由此形成了复杂的异构数据库环境。在这种背景下,如何高效、准确、安全地在这些异构数据库之间进行数据转换与集成,并提供稳定可靠的数据处理与存储支持服务,成为企业数据治理与价值挖掘的关键挑战。本文旨在探讨异构数据库系统数据转换方法的设计思路与实现路径,并阐述其在数据处理与存储支持服务中的应用。
一、 异构数据转换的核心挑战
在异构数据库间进行数据转换,主要面临以下核心挑战:
- 数据模型异构性:关系模型、文档模型、键值模型、图模型等数据结构的根本差异。
- 数据类型与语义不匹配:相同名称的数据类型(如“日期”、“字符串”)在不同数据库中可能存在精度、格式或语义上的差异。
- 数据模式(Schema)的动态性与刚性:NoSQL数据库可能模式灵活或无模式,而关系数据库模式严格,两者转换时需要处理模式映射与演化。
- 数据一致性与完整性约束:事务特性、主外键约束等在异构环境中的迁移与保持问题。
- 转换性能与效率:海量数据迁移时的吞吐量、延迟以及对源端和目标端系统性能的影响。
二、 数据转换方法的设计框架
一个健壮的异构数据转换系统设计通常遵循以下分层框架:
1. 元数据管理层
- 功能:统一采集、管理和映射源数据库与目标数据库的元数据信息,包括表结构、字段类型、约束关系、数据字典等。
- 实现:构建中央元数据仓库,通过适配器连接各类数据库的元数据接口(如INFORMATION_SCHEMA, system tables),并建立可视化映射规则配置界面。
2. 转换规则与映射引擎层
- 功能:定义和执行从源到目标的数据转换规则。这是设计的核心。
- 关键设计:
- 结构映射:定义表到集合、行到文档、列到字段等对象级映射。
- 数据类型转换器:为每对“源类型-目标类型”开发可插拔的转换器,处理格式、精度、编码等转换(如Oracle的DATE到MongoDB的ISODate)。
- 语义转换与清洗:通过内置函数或自定义脚本(如SQL, JavaScript, Python)进行数据清洗、计算派生字段、合并拆分字段等。
- 约束处理策略:定义如何处理非空约束、唯一性约束、外键关系等在目标端的实现或软化策略。
3. 数据抽取、转换与加载(ETL/ELT)执行引擎层
- 功能:负责高效执行数据移动与转换过程。
- 实现考量:
- 抽取策略:支持全量抽取、基于时间戳/增量标识的增量抽取、以及变更数据捕获(CDC)。
- 转换执行模式:支持传统的ETL(在专用引擎中转换后加载)和现代的ELT(先加载到目标端临时区,利用目标端强大计算能力转换)。
- 任务调度与监控:提供可视化的工作流编排、任务调度、执行状态监控、错误报警与重试机制。
4. 数据处理与存储支持服务层
- 功能:作为整个数据转换系统的服务化输出,为上层应用提供统一的数据处理与存储访问接口。
- 关键服务:
- 统一查询服务:提供SQL或类SQL接口,背后将查询翻译并下发到相应的异构数据库执行(联邦查询)。
- 数据同步服务:提供近实时或定期的单向/双向数据同步能力,保持异构系统间数据状态的一致性。
- 数据备份与归档服务:利用转换通道,将在线数据转换格式后备份到成本更低的存储系统(如对象存储)。
- 缓存与加速服务:将热点数据转换后加载到高性能缓存(如Redis)中,支持应用高速访问。
三、 关键技术实现要点
- 适配器模式(Adapter Pattern)的广泛应用:为每种数据库开发统一的连接、元数据读取、数据读写适配器,是降低系统耦合度的关键。
- 中间格式的利用:在复杂转换链中,可先将数据抽取为一种中间格式(如Avro, Parquet, JSON),再进行统一处理,简化转换逻辑。
- 分布式计算框架集成:对于超大规模数据转换,执行引擎可以与Spark、Flink等框架集成,利用其分布式计算能力进行并行转换,提升吞吐量。
- 事务与一致性保障:对于要求严格一致性的场景,需设计分布式事务补偿机制(如Saga模式)或确保转换作业在业务低峰期以原子性批次执行。
- 可观测性建设:集成完善的日志、指标(Metrics)和追踪(Tracing),实时掌握数据转换的血缘关系、数据质量指标和系统性能状态。
四、 实践应用场景
- 数据湖/数据仓库构建:将分散在业务数据库(OLTP)中的多源异构数据,经过清洗转换后,集中加载到数据湖(如基于HDFS/对象存储)或企业数据仓库(如Snowflake, BigQuery)中,支撑分析与决策。
- 微服务架构下的数据共享:不同微服务使用不同的数据库(如订单服务用MySQL,产品目录用MongoDB),通过数据转换与同步服务,在保证服务自治的满足跨服务数据查询需求。
- 系统迁移与升级:在数据库版本升级或更换数据库品牌时,平滑完成历史数据的迁移与转换。
- 多模数据库支持:为应对复杂业务逻辑,同一应用可能需要同时访问关系型和文档型数据,转换系统可提供透明的数据格式转换支持。
五、 与展望
异构数据库系统的数据转换不仅是简单的数据搬家,而是一个涉及数据建模、语义理解、工程效率和服务化能力的综合性课题。一个优秀的设计与实现需要平衡灵活性、性能、一致性和易用性。随着云原生和AI技术的发展,数据转换方法将呈现以下趋势:更智能的元数据发现与映射推荐、基于数据湖格式(Iceberg, Hudi)的免转换统一存储层、以及Serverless化、弹性伸缩的转换即服务(TaaS)模式,从而进一步降低企业进行数据集成与价值挖掘的技术门槛和运营成本,夯实数据处理与存储支持服务的基石。









